We build conversational AI agents for insurance companies. Our agents handle broker questions, guide people through claims and caregiving situations, process endorsements, automate quoting workflows. The stakes are real — regulatory compliance, customer trust, accuracy.
Early on, we ran into a problem that had nothing to do with the agents themselves. We’d deploy an agent, the customer would give feedback, we’d adjust, and then different people on their team would give conflicting feedback. Too long. Too short. More detail. Less detail. Every fix created a new problem.
The agent wasn’t broken. The issue was that nobody — not us, not the customer — had clearly defined what “correct” meant for that agent, for those users, in those situations.
That’s when we realized: the hardest part of building a good AI agent isn’t the AI. It’s defining what success looks like.
The evaluation framework
Once we understood the problem, we built a framework around it. The core idea is straightforward: define what “good” looks like for each agent, then measure every response against that definition.
Rubrics are the quality standards. Each agent gets a set of rules — specific, testable behaviors developed with the customer. Not generic metrics like “accuracy” or “helpfulness.” Concrete things:
- Emergency situations require immediate, concise guidance
- The agent should escalate when it detects distress
- Responses stay within the agent’s defined scope — no making things up
Each rule has a severity level. High for safety-critical behavior. Medium for user experience. Low for preferences. Severity drives how much weight each rule carries in the overall score.
We learned early that you need fewer rules than you think. We started with 18 rules for one agent and the results were noisy — rules contradicted each other, workflow-specific checks got mixed in with universal standards. We restructured to a hard cap: 3 to 6 universal rules per agent, with workflow-specific criteria attached to individual test scenarios. Cleaner signal, more useful results.
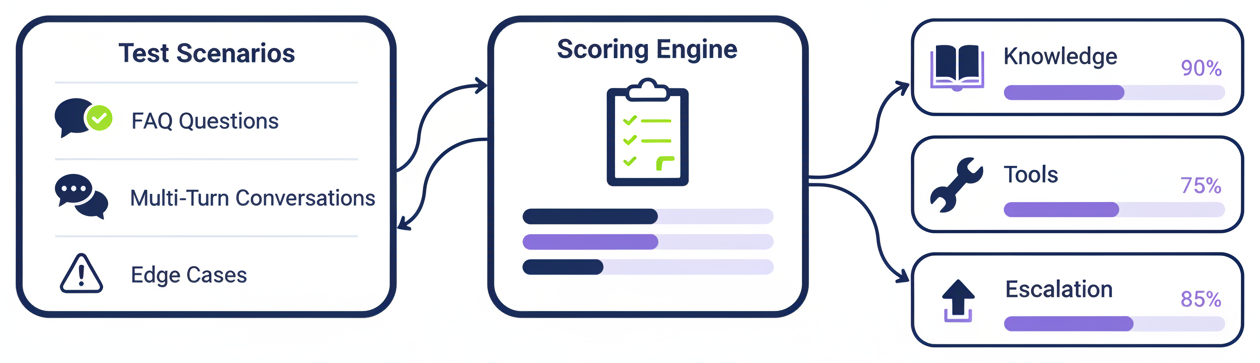
Test sets are the scenarios. Questions, multi-step conversations, edge cases — covering how real users actually interact with the agent. Each scenario has its own success criteria: did the agent ask for the right information? Did it use the right tool? Did it escalate when it should have?
When we run an evaluation, every scenario goes to the agent. Every response gets scored against every rule. The results break down by component — how the agent handles a specific knowledge base, a specific tool, a specific type of interaction. Where is it strong? Where does it fall short? The scoring shows exactly where to focus.
Why LLM judges
We use LLM judges for scoring instead of deterministic checks. The reason is context.
If someone calls about a family member in crisis, three concise bullet points with critical information is exactly the right response. That same terse format for a routine question about policy renewal feels cold. A pattern-matching check can’t tell the difference. An LLM judge can evaluate whether the response was appropriate for the situation — intent, not just structure.
Each evaluation run makes an LLM call for every test-rule combination. There’s a real cost to that, and we’ve optimized around it. But the alternative — deterministic checks that can’t understand context — produces results you can’t trust. When you’re using evaluation scores to decide whether an agent is ready for production, you need judges that understand what they’re evaluating.
Four ways to test
We test agents in four different modes because no single mode tells the full story.
Single-turn is the simplest — send a question, get a response, score it. Good for checking whether the agent knows the right answers and follows the rules.
Multi-turn simulated is where it gets interesting. An LLM plays the customer based on a persona description. The agent responds naturally over multiple turns. The evaluator scores the full conversation — not just individual answers, but how the interaction unfolded. Did the agent carry context? Did it escalate at the right moment? Did it use its tools correctly?
Multi-turn replay pulls real conversations from production and replays them through the current version of the agent. This is regression testing for conversations — did we make things better or worse with the latest changes?
Voice simulation is the newest mode. For our voice agents, we rebuilt the entire voice pipeline on the simulation side — text-to-speech, audio streaming, speech-to-text, transcription capture. The agent speaks, the simulator hears it, processes it, and speaks back. A full conversation, over audio, evaluated end-to-end. Until we built this, voice agents were a blind spot — every web chat conversation flowed through our analytics platform, but voice was invisible.
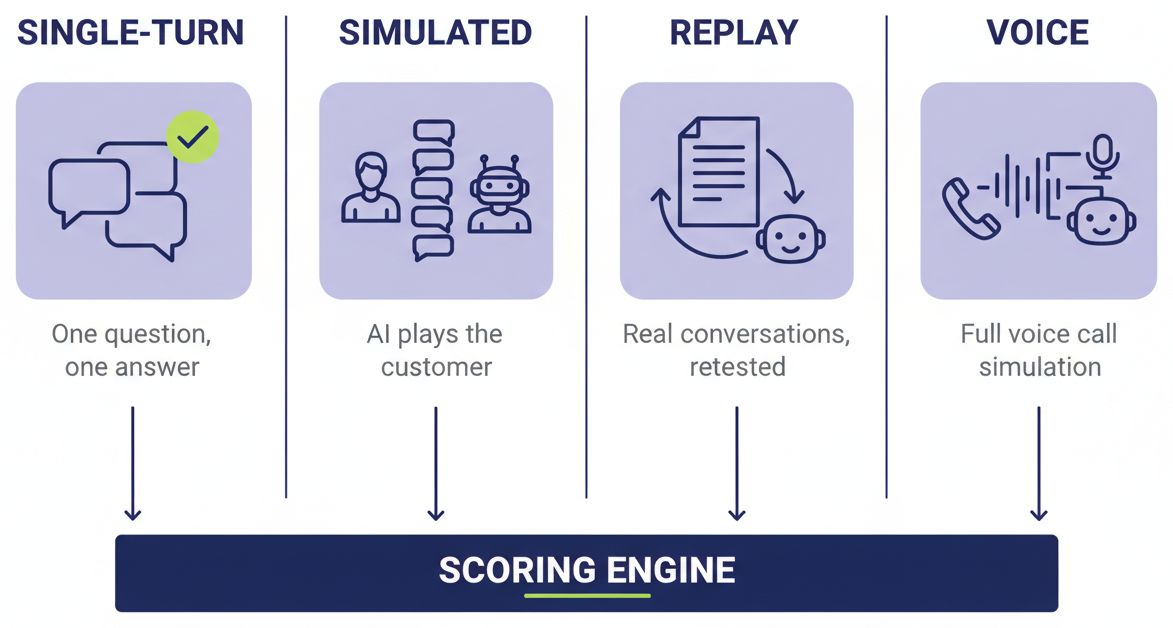
Single-turn tells you the agent knows the right answers. Multi-turn tells you the agent can do the job. Voice tells you it can do the job over a phone call. Replay tells you whether your changes made things better.
What this looks like in practice
Here’s what changed once evaluations were part of how we operate.
One customer’s agent went live this month — not because we told them it was ready, but because they saw the evaluation results and felt confident enough to deploy on their own. That was a first. No hand-holding, no “trust us” — the numbers spoke for themselves.
For another customer, we ran 52 test scenarios covering over 500 individual criteria and rubric checks. Overall accuracy landed around 89-90%. The gaps were specific and actionable: the agent was trying to handle too much complexity for its architecture, and some success criteria needed simplifying. We didn’t guess where the problems were. We measured them, and now both we and the customer can see exactly what needs work.
The evaluation framework also surfaced something we hadn’t expected: conflicting requirements. “Be comprehensive” and “be brief” can’t both be satisfied in every situation. Getting those conflicts out of the implicit and into the explicit — having a real conversation with the customer about tradeoffs — resolved friction that had been building for months.
The improvement loop
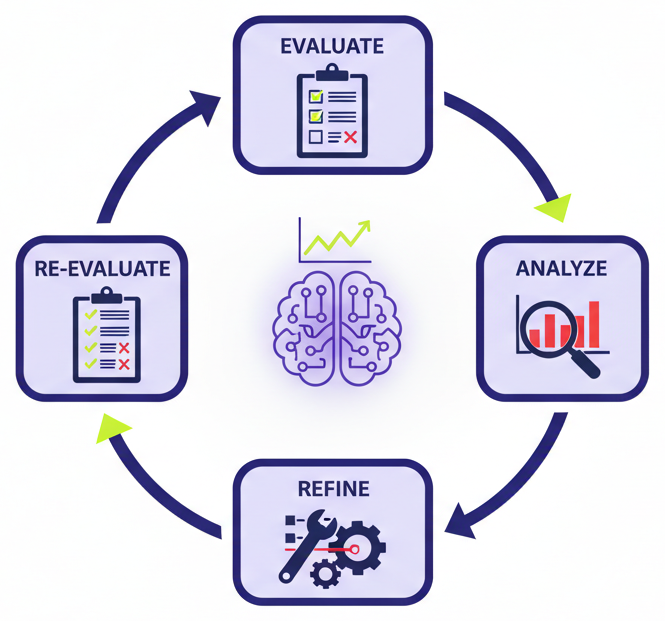
The evaluation framework started as a way to measure. It’s becoming a way to improve.
Our agent builder can read an agent’s full context — its system prompt, its tools, its knowledge bases — and generate a complete evaluation from scratch. Rubric rules, test scenarios, success criteria. What used to take days of manual work now takes minutes, and every agent we deploy starts with a real evaluation baseline from day one.
But the bigger shift is what happens after the scores come in. The system reads the evaluation results, identifies the failure patterns, and adjusts the agent — refining prompts, tool configurations, behavior — then re-evaluates. It’s an improvement loop: evaluate, identify failures, fix, re-evaluate, repeat. Agents improving agents.
We’ve also built this into our development workflow. Our engineering sessions have their own tools for working with rubrics, analyzing test results, and refining agents based on what the evaluations surface. The full end-to-end automated improvement pipeline — where an agent can be built, evaluated, and refined without manual intervention — is something we’re rolling out to the team now.
Why we’re building this
There are a lot of companies building AI agents. A lot of tools, a lot of platforms, a lot of solutions.
What makes what we’re building different isn’t the AI itself. It’s that we understand the problems our customers are dealing with — the specific workflows, the regulatory requirements, the situations their users bring to these agents. We’re not delivering chatbots. We’re delivering efficiency gains and revenue gains into their businesses.
Evaluations are how we prove that. They give us confidence that what we’re building actually works. They give our customers transparency into how the agent performs, where it falls short, and how it’s improving. And they give our team clear direction — not “make it better,” but specific criteria, specific failures, specific next steps.
If you can define what success looks like, you can build toward it. If you can measure it, you can prove it to your customers. And if you can automate the measurement and the improvement, you can scale it to every agent you deploy.
That’s the system we built. It started with a customer who needed us to define what “correct” meant. Now it’s how we build everything.
We build AI agents for insurance companies at Indemn. If you’re interested in how we work or want to see what this looks like for your organization, reach out.